Share it with your network.
Digitization has changed the way we process and analyze information. There is an exponential increase in online availability of information. From web pages to emails, science journals, e-books, learning content, news and social media are all full of textual data. The idea is to create, analyze and report information fast. This is when automated text classification steps up.
Text classification is a smart classification of text into categories. And, using machine learning to automate these tasks, just makes the whole process super-fast and efficient. Artificial Intelligence and Machine learning are arguably the most beneficial technologies to have gained momentum in recent times. They are finding applications everywhere. As Jeff Bezos said in his annual shareholder's letter,
Over the past decades, computers have broadly automated tasks that programmers could describe with clear rules and algorithms. Modern machine learning techniques now allow us to do the same for tasks where describing the precise rules is much harder.
- Jeff Bezos
Talking particularly about automated text classification, we have already written about the technology behind it and its applications. We are now updating our text classifier. In this post, we talk about the technology, applications, customization, and segmentation related to our automated text classification API.
Intent, emotion and sentiment analysis of textual data are some of the most important parts of text classification. These use cases have made significant buzz among the machine intelligence enthusiasts. We have developed separate classifiers for each such category as their study is a huge topic in itself. Text classifier can operate on a variety of textual datasets. You can train the classifier with tagged data or operate on the raw unstructured text as well. Both of these categories have numerous application of themselves.
Supervised Text Classification
Supervised classification of text is done when you have defined the classification categories. It works on training and testing principle. We feed labeled data to the machine learning algorithm to work on. The algorithm is trained on the labeled dataset and gives the desired output(the pre-defined categories). During the testing phase, the algorithm is fed with unobserved data and classifies them into categories based on the training phase.
Spam filtering of emails is one example of supervised classification. The incoming email is automatically categorized based on its content. Language detection, intent, emotion and sentiment analysis are all based on supervised systems. It can operate for special use cases such as identifying emergency situation by analyzing millions of online information. It is a needle in the haystack problem. We proposed a smart public transportation system to identify such situations. To identify emergency situation among millions of online conversation, the classifier has to be trained with high accuracy. It needs special loss functions, sampling at training time and methods like building a stack of multiple classifiers each refining the results of previous one to solve this problem.
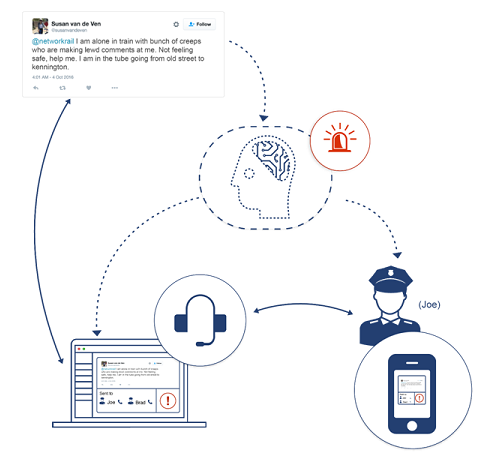
Supervised classification is basically asking computers to imitate humans. The algorithms are given a set of tagged/categorized text (also called train set) based on which they generate AI models, these models when further given the new untagged text, can automatically classify them. Several of our APIs, are developed with supervised systems. The text classifier is currently trained for a set of generic 150 categories.
Unsupervised Text Classification
Unsupervised classification is done without providing external information. Here the algorithms try to discover natural structure in data. Please note that natural structure might not be exactly what humans think of as logical division. The algorithm looks for similar patterns and structures in the data points and groups them into clusters. The classification of the data is done based on the clusters formed. Take web search for an example. The algorithm makes clusters based on the search term and presents them as results to the user.
Every data point is embedded into the hyperspace and you can visualize them on TensorBoard. The image below is based on a twitter study we did on Reliance Jio, an Indian telecom company.

The data exploration is done to find similar data points based on textual similarity. These similar data points for a cluster of nearest neighbors. The image below shows the nearest neighbors of the tweet "reliance jio prime membership at rs 99 : here's how to get rs 100 cashback...".

As you can see, the accompanying tweets are similar to the labeled one. This cluster if one category of similar tweets. Unsupervised classification comes handy while generating insights from textual data. It is highly customizable as no tagging is required. It can operate on any textual data without the need of training and tagging it. Thus, the unsupervised classification is language agnostic.
Custom Text Classification
A lot of the times, the biggest hindrance to use Machine learning is the unavailability of a data-set. There are many people who want to use AI for categorizing data but that needs making a data-set giving rise to a situation similar to a chicken-egg problem. Custom text classification is one of the best ways to build your own text classifier without any data set.
In ParallelDots’ latest research work, we have proposed a method to do zero-shot learning on text, where an algorithm trained to learn relationships between sentences and their categories on a large noisy dataset can be made to generalize to new categories or even new datasets. We call the paradigm “Train Once, Test Anywhere”. We also propose multiple neural network algorithms that can take advantage of this training methodology and get good results on different datasets. The best method uses an LSTM model for the task of learning relationships. The idea is if one can model the concept of “belongingness” between sentences and classes, the knowledge is useful for unseen classes or even unseen datasets.
How to build a custom text classifier?
To build your own custom text classifier, you need to first sign up for a ParallelDots account and log in to your dashboard.
Check the demo to try our custom classifier.
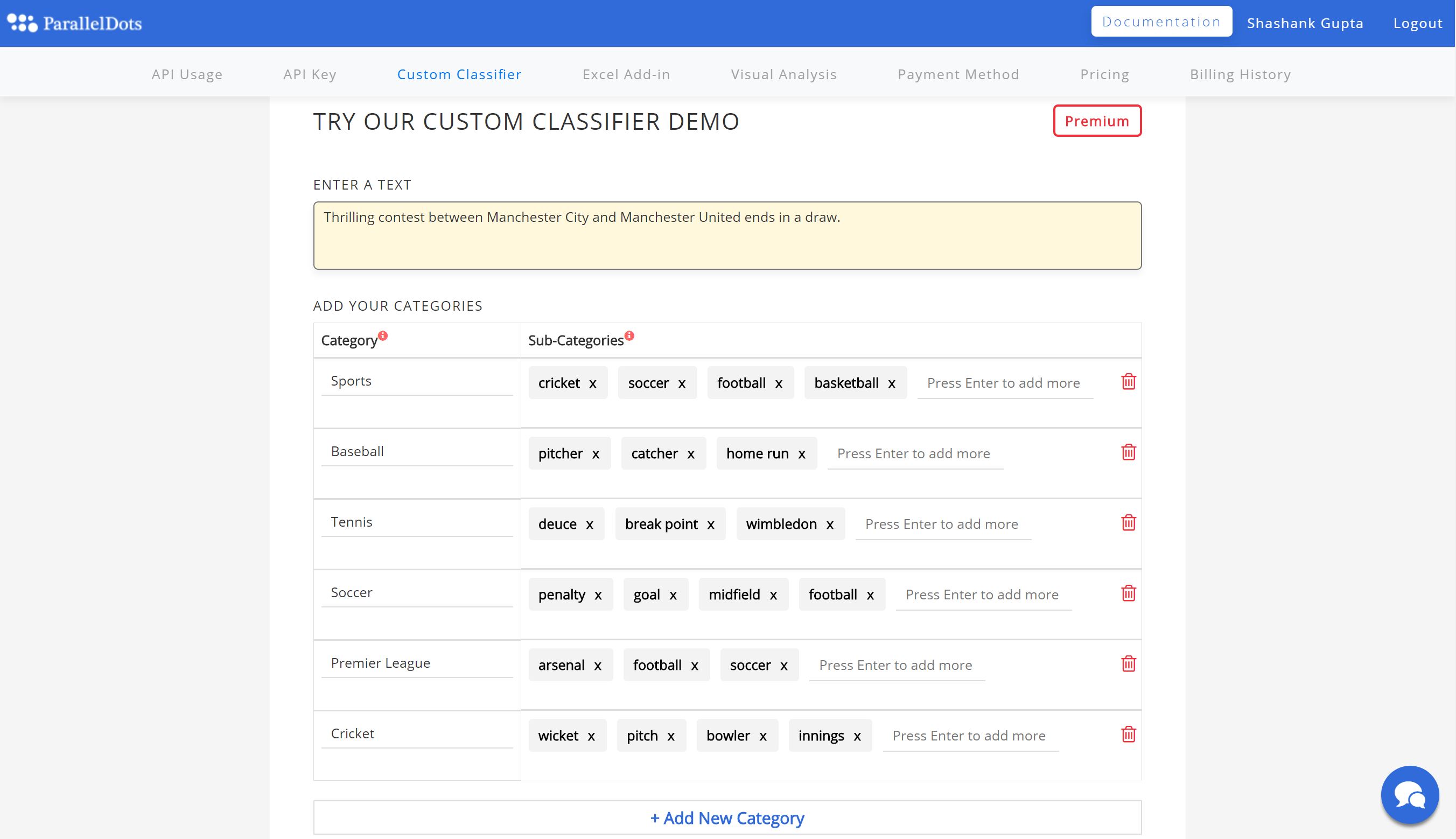
You can check the accuracy of classification by analyzing a sample of your text and tweak your category list as much as you want before publishing them. Once the categories are published, you will get an application id which will let you use the custom classifier API.
Considering that data labeling and preparation can be a limitation, Custom Classifier can be a great tool to build a text classifier without much investment. We also believe that it will bring down the threshold of building practical machine learning models that can applied across industries solving a variety of use-cases.
As an AI research group, we are constantly developing cutting-edge technologies to make processes simpler and faster. Text classification is one such technology which has enormous potential in coming future. As more and more information is dumped on the internet, it is up to the intelligent machine algorithms to make analyzing and representing this information easily. The future of machine intelligence is surely exciting, subscribe to our newsletter to get more such information in your inbox.
We hope you liked the article. Please Sign Up for a free Komprehend account to start your AI journey. You can also check demo’s of Komprehend AI APIs here.


