Share it with your network.
2020 [and the first half of 2021] was a black swan. Families, Societies and companies had to face things they couldn’t have conceived of. In this post, I will try to highlight how ParallelDots AI team has been adapting in this period and building for the next generation of our retail AI solutions.
ParallelDots went into the full remote work mode in February 2020 and since then the team hasn’t met physically for a day. We had always been a very tightly knit unit before that and thus the first few weeks were totally spent in building a remote working culture. We had to think about better communication and a very different ownership structure. Given that the company was also dealing with a business shock, these weeks were hard. I personally am proud of the way our team handled the pressure and not just adjusted but evolved to become the top technology churning machine it has always been. Just a few weeks of tweaks and we were back being awesome.
Challenges for AI team [circa March 2020]
[You might find the ‘why’ of different AI algorithms and systems we are building as boring, I know because I would have 😉 , in case you are just interested in the ‘how’, or all the new cool tech and algorithms section, move down to the section ‘New Systems and Algorithms’]
ParallelDots AI team role is solving different problems which bottleneck our AI training and deployment infrastructure at ParallelDots. You can divide these challenges into : A. AI training and Accuracy Bottlenecks [or Research Bottlenecks] and B. Deployment/Inference Bottlenecks [or MLOPS Bottlenecks as we call them] . In the beginning of 2020, while our AI technology was already processing over a million images per month, some challenges that we were expected to solve to make it scale up were :
- Deploying an inference infrastructure which can automatically scale up in case there are too many retail images to process so as to preserve our SLAs while making sure the deployment scaled down for small workloads. GPUs are costly machines and having a static [or off-the-shelf or manual devops] infrastructure is a tightrope between meeting SLAs and avoiding high costs.
- Making our retail computer vision algorithms run on phone. We had always thought of a new product where on-edge AI could be used in phone at small retail outlets with slow internet connection for Billing/GRN/Inventory Management. Not just that, some of our prospective shelfwatch clients wanted deployments that could be used within shops for quick inference without the wait for image upload and process. We were aware that if we could make our retail AI algorithms run on phones, it would help us build our dream second product but would also help our existing product get new clients. Both the above challenges are MLOPS challenges as we call them.
- Detecting Size variants of products in images. Another challenge was to detect size level variations for a product in retail images. As an example, let’s say that you have image for a shelf of chips and you have to detect the counts of not just Lay’s magic masala using AI, but also give a split between 10 INR / 20 INR / 30 INR packets of Lay’s Magic masala in your analysis. For people who have not worked in Computer Vision, this might look like an obvious and simple next problem to solve given the AI can detect product on shelf and classify them as brands with very high accuracy. But you know the famous XKCD #1425 [There’s always a relevant XKCD for everything]. Relevant XKCD
- Verifying parts of Point-Of-Sale-Materials. Another part of analyzing shelf images apart from detecting and identifying products on shelf is verifying presence of various Point of Sale Materials on shelf. These point of sale materials are things you would often see in a retail or kirana store around you like shelf strips, cutouts, posters, gandolas and demo racks. We used Deep Keypoint matching for such matches for a very long time and it used to work well. However, with time customers had asked us not just to verify POSM in shelf images but also to point out the missing pieces which a merchandizer might have missed in a POSM. For example, a merchandizer might have missed placing a poster on a demo rack or it might have gotten removed in shop due to some accident. To do this very accurately at a level to which image classification works, we needed an algorithm that works everywhere without training as POSMs change within weeks/months.
- Training more accurate shelf product detectors. Retail Shelf Computer Vision has moved to the technology of having a generic shelf object detector [extract out any shelf object without classifying it] in the first step and then classifying the products then extracted in the second step to avoid the problems one step detectors + classifiers create [Massive product skewness on shelves creating bad classification outputs / training on a lot of data per project and no incremental gain from the AI getting better from previous projects and so on]. We already had such a system of a generic shelf object detector and a state of the art classifier in second step in 2019, but the output box shapes of the shelf object detector could have been better.
- Using past AI training and error corrections to train classifiers both better and faster. We train so many classifiers [models that classify shelf objects extracted by the step 1 algorithm into one of the product brands we require]. Is there a way to use all the training data we collect, including mistakes of past classifiers to create an algorithm that can help train new classifiers both fast and more accurately is a question that is always around. The four research problems [3-6] you have found reflected new requirements of our shelfwatch product [3,4] and bettering the existing stack [5,6]. Now there was also a set of research problems from our NLP APIs stack.
- A more generic Sentiment Analysis API. The Sentiment Analysis API we had online was trained on in-house annotated tweets and thus despite having great accuracy could fail on more domain specific stuff like say political or finance articles. Unlike tweets such different domain articles are hard to annotate by people not experienced in a dataset’s domain. Using a lot of unannotated data to train classifiers which could work across domain has been an ever existing challenge.
- A new targeted sentiment API. Aspect based sentiment analysis has been around for sometime. We finally had an inhouse annotated dataset for such analysis, but our goal was somewhat more specific. We wanted to build an API where you give a sentence “The apple was not tasty but the orange was really yum.” would give a negative output when analyzed for “Apple” or Positive when analyzed for orange. We thus were targeting to build a state of the art Aspect Based Sentiment Analysis algorithm.
Now that I have bored you with the details of challenges we were trying to solve, lets come to the interesting part. Our new MLOPS platforms and algorithms.
New Systems and Algorithms
Let me introduce you to my new friends, some awesome technology systems and AI algorithms we have developed and deployed over the last time to tackle the bottlenecks.
Mobile Product Recognition AI or Mobile Shelf Recognition AI
Introduction to ParallelDots Oogashop – Link
We have built and deployed not one, but two different types of AI algorithms on mobile devices. You might have seen our extremely viral posts few days back where we demoed mobile phone billing and talked about offline shelf audits.
Here’s the link to ShelfWatch’s On-Device Image Recognition Feature (ODIN) – Link
(Article)
Essentially, these AI models are scaled down versions of the models we deploy on cloud. With some loss in accuracy, these models are now small enough to run on a phone GPU [which is much smaller than a serve GPU]. Tensorflow’s new mobile deployment frameworks are what we use to deploy these models in our OOGASHOP and ShelfWatch app respectively.
(Paper) Compact Retail Shelf Segmentation for Mobile Deployment – Link
Pratyush Kumar, Muktabh Mayank Srivastava
Autoscaling Cloud AI Inference
When the shops open at around 11 AM [11AMs for different time zones that is, wherever in the world our clients have their salesforce or merchandizers ], our servers face an insane load of merchandizers uploading photos on our cloud to process and tell them about their retail execution score. And then after 11 PM when the retail stores close, we hardly have enough AI inference workload. While Lambda like autoscaling has been introduced by many providers, we wanted a cloud independent autoscaling technique for our AI inference infrastructure. When there are more images in our processing queue, we need more GPUs crunching them, otherwise just one or maybe none. To do this, the entire AI inference layer was moved to Docker, Kubernetes and KEDA based architecture where arbitrary number of new GPUs can be spawned based on the workload. No more a tightrope of trying to manage company’s SLA and saving $$ on the costly to run GPU machines.
Bettering the Shelf Object Detection Algorithms
(Paper) Learning Gaussian Maps for Dense Object Detection – Link
Sonaal Kant
We had been using simple Faster RCNNs trained for shelf object extraction earlier : Simple Object Detection Baseline Paper . It worked well for many use cases. but we needed more state of art approaches. In 2020 our team discovered a new method to use Gaussian Maps to get state of the art results. This work [later published at BMVC, one of the top Computer Vision conferences BMVC website ] helped us get not just satisfactory but the best possible results on a shelf object detection.
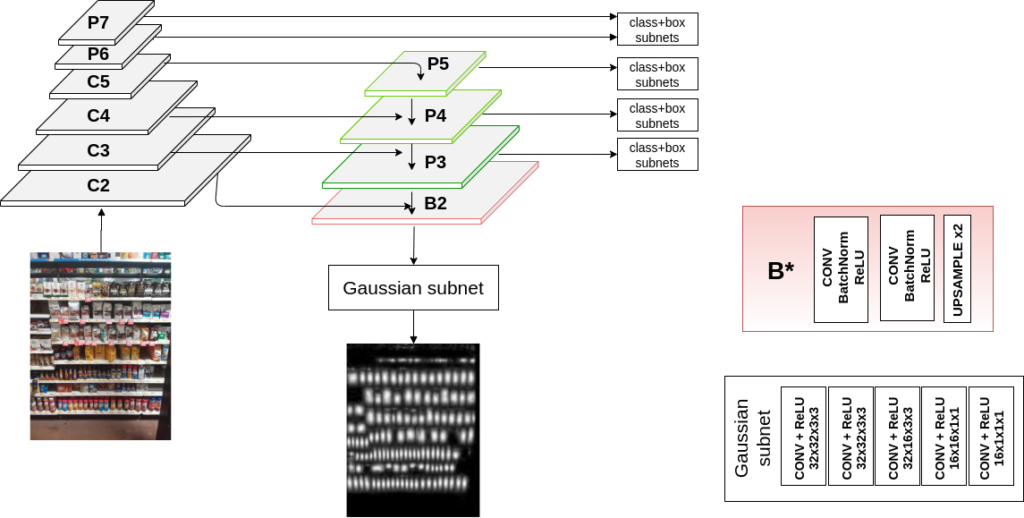
The trick essentially is to use gaussian maps training as an auxiliary loss to object detection. This makes the boxes for different products much more precise.
Another question we have been trying to address for a long time in terms of shelf object detection has been, now that the need to recognize products has been moved to a downstream task and the task is to draw boxes over all possible products, is there a way for using the noises and distortions contained in a huge unannotated dataset to better shelf object detection. In a recent work, [mentioned at RetailVision workshop at CVPR 2021 Retail Vision Workshop ], we use our humongous repository of unannnotated shelf images to better the accuracy of shelf object detection task.
(Paper) Semi-supervised Learning for Dense Object Detection in Retail Scenes – Link
Jaydeep Chauhan, Srikrishna Varadarajan, Muktabh Mayank Srivastava
Psuedolabel based student training is a trick that we have used in multiple fields, not for shelf object detection.While other self learning techniques require large batchsizes to be loaded on GPUs thus making it hard for a company like limited hardware like ParallelDots to try them out, pseudolabels is what we have adapted as our trick to do single GPU self learning.

Bettering Classification Accuracy
We have used multiple tricks in the past to train accurate classifiers with high accuracy.
(Paper) Bag Of Tricks for Retail Product Image Classification – Link, which illustrates how we train classifiers with high accuracy.
Muktabh Mayank Srivastava
All boxes that the shelf object detector extracts from a shelf image are passed through this classifier to infer the brand of product.

However, with the frequently changing catalogues of shop, our product classifier needs to evolve to do things a bit differently. Training a classifier is resource intensive, with products quickly adding or removing from catalogues of stores, we need a classifier that can be trained fast and be more accurate or at least as accurate as the methods involving finetuning of the full backbone. This sounds like having ones cake and rating it too, and that is what self learning techniques have been shown to do in Deep Learning. We have been trying to use concepts of Self Learning to create classifiers which can be trained very lightly.
(Paper) Using Contrastive Learning and Pseudolabels to learn representations for Retail Product Image Classification – Link
Muktabh Mayank Srivastava
The trick we use here is employing the huge repository of retail product images we have [both annotated and unannotated] to train a representation learner, whose output can be fed to a simple Machine Learning classifier for training. Such learnt feature representations work quite well. How cool is training a small logistic regression classifier to classify retail images. Unfortunately, we have over 20 times more images for such tasks, therefore right now our accuracy achieved is limited to the limited hardware infrastructure to do such self learning and still we beat state of the art on many [not all] datasets.

Size based inference on Shelf Images

While we have been detecting brands of different products seen in shelf images, a recent spec that we have tried to solve is to reason about what size variant of a product is the product that we depend. For example, while Computer Vision pipeline detects a Lays Magic Masala on the shelf and classifies it as Lays Magic Masala, how do we know if it is 50 Gram variant or 100 Gram variant or 200 Gram variant of the product. We thus include a third downstream task to guess the size variant of the shelf. This pipeline takes the different boxes extracted from the shelf, their brands and create features which can be used to guess the size. As is obvious, you cannot use bounding box coordinates or area for such reasoning as images can be taken from any distance. We use features like aspect ratio and area ratio between boxes of different groups to infer size variant.
(Paper) Machine Learning approaches to do size based reasoning on Retail Shelf objects to classify product variants – Link
Muktabh Mayank Srivastava, Pratyush Kumar
A lot of feature engineering tricks are used to train the two variants of the reasoning task : Using XGBOOST over binned features and using a Neural Network over Gaussian mixture model derived features.

Reasoning about Point of Sales Materials
When you walk into a retail store, you would notice different POSM materials : shelf strips, cutouts, posters, gandolas and demo racks.

While we have been using Deep Learning based keypoint representation matching for verifying the POSM presence in an image, there was a task to reason about POSM part by part. That is in the above example for example, we might be needed to check if the product photograph towards the right in the ideal shelf strip in present on a real world placement or not. We call this “Part” detection after POSM verification.
(Paper) Using Keypoint Matching and Interactive Self Attention Network to verify Retail POSMs – Link
Harshita Seth, Sonaal Kant, Muktabh Mayank Srivastava
Essentially since POSM changes very fast weekly/monthly, you cannot ever get a lot of data to train algorithms for each POSM. So we need algorithms that train in a way on existing datasets so that they can be applied on any dataset. That is our aim with the recent work of self attention network for POSMs. We use matched keypoints [on ideal POSM image and real word image] and their descriptors [from both images] as input for each part separately to determine exact presence.

A Sentiment Analysis API that works on any domain data
When training a model to be deployed as a sentiment analysis API, you cannot really get data from different domains annotated. For example, the previous sentiment analysis model we had was a large language model finetuned over 10-15k odd tweets we annotated in-house. So the algorithm has hardly seen sentiment expressed in different domains while learning. We tried using Self Learning to make our sentiment classification algorithm sturdy to domain change. Take 2 Million + unannotated sentence, run a older version of classifier to create pseudolabels and train a new classifier to learn these pseudolabels and boom.. you have a sentiment classifier which is much more domain robust, while its accuracy in the initial domain stays the same. Sounds too good to be true, check out our work :
(Paper) Using Psuedolabels for training Sentiment Classifiers makes the model generalize better across datasets – Link
Natesh Reddy, Muktabh Mayank Srivastava
Making a state of the art method to detect targeted sentiment
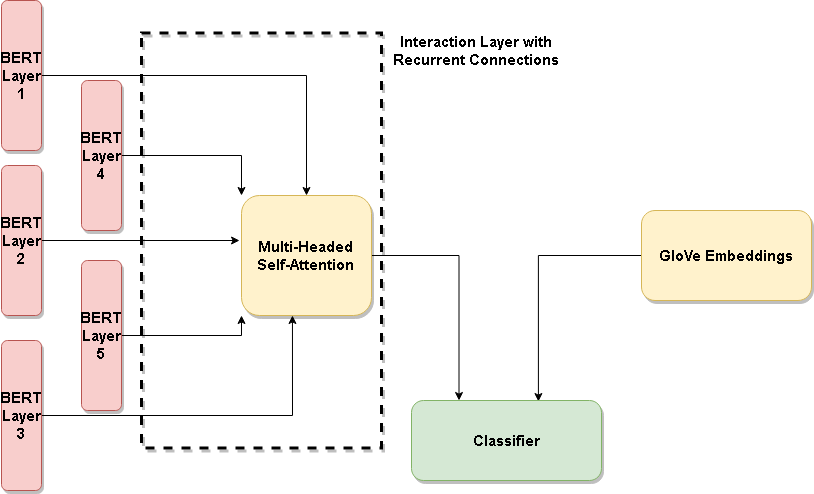
For us, in NLP API business, targeted sentiment is when you have the sentence “Apple wasn’t that tasty, but orange was good”, a classifier returns negative when it gets input “apple” and positive if it gets input orange. Basically, sentiment directed towards an object in a sentence. We have developed a new method that detects targeted sentiment and which will be soon available as a NLP API. The research field corresponds to Aspect Based sentiment analysis and our recent work gets state of the art results in multiple datasets, just by finetuning an architecture comparing contextual [BERT] and non-contextual [GloVe]. The sentiment is hidden in context somewhere, right ?
(Paper) Does BERT Understand Sentiment? Leveraging Comparisons Between Contextual and Non-Contextual Embeddings to Improve Aspect-Based Sentiment Models – Link
Natesh Reddy, Pranaydeep Singh, Muktabh Mayank Srivastava

Onwards and Upwards
Hope you liked the new technology that we have developed last year. Very happy to answer questions if you have any. We continue to develop new and exciting technology and are working on some new cool Machine Learning problems like Graph Neural Networks for Retail Recommendation, Out-Of-Distribution Image Classification and Language Models. We are hiring as well, write to us on careers@paralleldots.com or apply on our AngelList page to join our AI team. You can apply if you want to be a Machine Learning Engineer, Backend Developer or AI Project Manger. ParallelDots AngelList


