Like this article? Share it with your network.
Named Entity Recognition (NER), or entity extraction is an NLP technique which locates and classifies the named entities present in the text. Named Entity Recognition classifies the named entities into pre-defined categories such as the names of persons, organizations, locations, quantities, monetary values, specialized terms, product terminology and expressions of times. Named Entity Recognition is a part of a broader field called Information Extraction. According to Wikipedia, Information Extraction is the task of automatically extracting structured information from any kind of text, structured and/or unstructured.
Natural Language Processing has observed a paradigm shift in accuracy through past few years. These great strides can largely be attributed to the advent of Deep Learning. In recent years, Recurrent Neural Network (RNN) models have been very successful in extracting out named entities from texts. NER has various applications in multiple industry verticals such as news and media industry, search engines, content recommendations, customer support and academia. We have written a detailed blog post on applications of NER previously.
In this post, we shall walk you through some milestone models and research papers concerning NER and also discuss the model we used to run our Entity Extraction API. You can take a demo here.
Some milestone models for Named Entity Recognition using Deep Learning
CRF Classifier
Stanford NLP Group's named entity recognizer is an implementation of linear chain Conditional Random Field (CRF) sequence models.

The CRF sequence models provided here do not precisely correspond to any published paper, but the correct paper to cite for the model and software is Incorporating Non-local Information into Information Extraction Systems by Gibbs Sampling by Jenny Rose Finkel et al. which was published in 2005. One can download their code as it is open source, but being under a GPL license, it cannot be a part of a proprietary system.
Maximum Entropy Approach
The maximum entropy framework estimates probabilities based on the principle of making as few assumptions as possible, other than the constraints imposed. Such constraints are derived from training data, expressing some relationship between features and outcome. The probability distribution that satisfies the above property is the one with the highest entropy.
This paper by HL Chieu and HT Ng presents a maximum entropy approach to the NER task, where NER not only made use of local context within a sentence but also made use of other occurrences of each word within the same document to extract useful features (global features). Such global features enhance the performance of NER.
Feedforward Neural Networks for NER
Simple feedforward neural networks like this can be a good baseline neural network model for NER. These models are pretty simple in the sense that they take embeddings of a set of words (3-grams , 5-grams ) from the language and try to predict whether the middle word is a named entity or not. ParallelDots' first ever NER model was based on this technique.
BiLSTM-CNNs
Jason Chiu et al. presented a novel neural network architecture in July 2016 that automatically detects word-level and character-level features using a hybrid bidirectional LSTM and CNN architecture, eliminating the need for most feature engineering.

Their model was competitive on the CoNLL-2003 dataset and surpasses the previously reported state of the art performance on the OntoNotes 5.0 dataset by 2.13 F1 points. By using two lexicons constructed from publicly-available sources, they established the new state-of-the-art performance with an F1 score of 91.62 on CoNLL-2003 and 86.28 on OntoNotes, surpassing systems that employ heavy feature engineering, proprietary lexicons, and rich entity linking information.
Multi Task Learning
Transfer and multi-task learning have traditionally focused on either a single source-target pair or very few, similar tasks. Kazuma Hashimoto et al. introduced a joint many-task model in late 2016, together with a strategy for successively growing its depth to solve increasingly complex tasks. Higher layers include shortcut connections to lower-level task predictions to reflect linguistic hierarchies.

The authors used a simple regularization term to allow for optimizing all model weights to improve one task's loss without exhibiting catastrophic interference of the other tasks. Their single end-to-end model obtained state-of-the-art or competitive results on five different tasks from tagging, parsing, relatedness, and entailment tasks. Similar MTL based models are being used to train NER with other NLP tasks as well.
Residual Stack BiLSTMs with biased decoding
Quan Tran et al. improved the state-of-the-art RNN models for NER by improving two aspects. The first one being the introduction of residual connections between the Stacked Recurrent Neural Network model to address the degradation problem of deep neural networks.
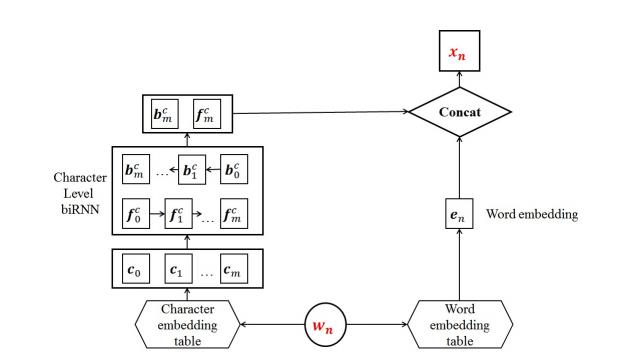
The second innovation was a bias decoding mechanism that allows the trained system to adapt to non-differentiable and externally computed objectives, such as the entity-based F-measure. Their model, Residual Stack BiLSTM, improved the state-of-the-art results for both Spanish and English languages on the standard CoNLL 2003 Shared Task NER dataset.
At Paralleldots, we used normal LSTMs for Named Entity Recognition for the last one year, but we have come up with a new model very recently. We now use Residual Stack BiLSTM to train our entity extraction API. Our internal data tagging team tagged approximately 2 million sentences crawled from internet with named entity on which we trained our model. For example, the sentence “This is a house that Jack built” is annotated with (Jack, Person) and “John and Kim are going to Miami” is annotated with (John; Person), (Kim; Person) and (Miami, Place).
Have a look at our entity extraction demo here:

In recent years, there has been a flurry of results showing deep learning techniques achieving state-of-the-art results in many natural language tasks such as language modeling, parsing and many others. At Paralleldots, we provide several NLP APIs. You can look at the demos here.


