Like this article? Share it with your network.
Named Entity Recognition (NER) is a particularly interesting branch of Natural Language Processing (NLP) and a subpart of Information Retrieval (IR). A NER model is trained to extract and classify certain occurrences in a piece of text into pre-defined categories. What are these categories? glad you asked. The categories can be thought of as the type of entities a NER model can extract. For example, it can be a name (of an organization, a person, a place...), measurement parameters, percentages, etc.

Komprehend has an industrial-grade NER API which works in the English language. However, the world is a diverse place and the English language doesn't always cut it. Keeping this in mind we recently added multilingual extraction capability to our current NER model. This post is going to discuss this new feature. We will also take an in-depth look at Named Entity Recognition's application and uses.
How does a Named Entity Recognition model work?
The image below gives a glimpse into the method employed to carry out Named Entity Recognition.

Our API uses deep learning technology. Below, you can find a brief description of our technology:
- Word Embeddings are trained on a huge text corpus our extensive crawling infrastructure collects from the open web. These embeddings are trained using either GloVe or Word2Vec algorithm. We use gloVe embeddings in production. This algorithm converts each word into a dense 100-dimensional vector. The Neural Network we train takes these Embeddings as inputs instead of words directly.
- Our internal data tagging team annotated a huge dataset of entities present in the data we have crawled. So for example, the sentence “This is a house that Jack built” is annotated with (Jack, Person) and “Ram and Shyam are going to Delhi” is annotated with (Ram, Person), (Shyam, Person) and (Delhi, Place). Our internal dataset has over 200,000 such annotated sentences.
- We then train a sequence labeling bidirectional LSTM on top of the tagged dataset mentioned above to predict whether each word in a sentence in an entity or not. An LSTM or Long Short Memory Network is a better RNN, which avoids gradient damping by converting general recurrence’s multiplication paradigm into addition paradigm.
- Attention layer was also tried in LSTM to see if it can help tell about important properties in a sentence which define a word as an entity. We are still refining the model with attention and the model in production is LSTM without attention.
Out of the total data given as input, 10% was used for testing the system and the remaining for training it. Our Neural Network model attains an F1 score of 92.8 when trained on Conll-03 dataset.
Multilingual Named Entity Recognition API in action
After the details of our architecture, let's look at the API in action. You can also test our model from a free demo hosted here.
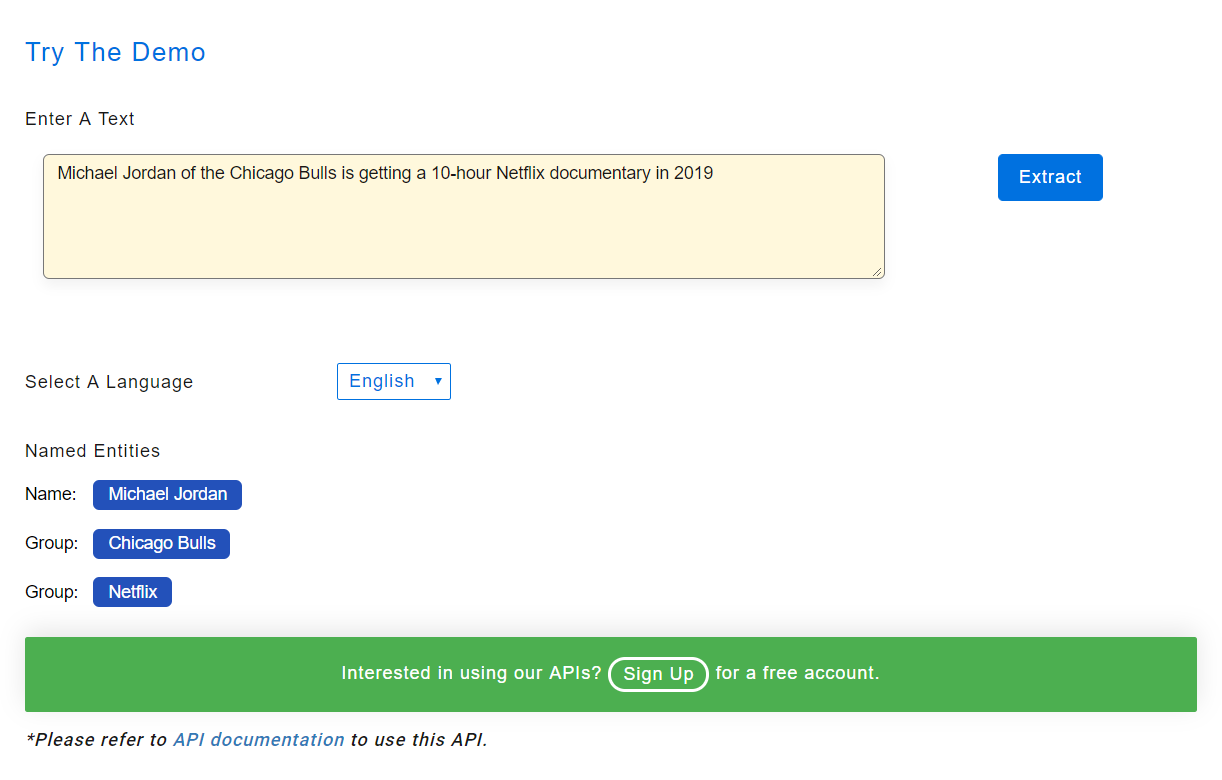

Named Entity Recognition- Spanish

Named Entity Recognition- Dutch

Named Entity Recognition- German
Industry applications of NER
Our NER API is truly industry agnostic with a wide range of applications. Let us have a look at some of them.
#1 Information Extraction System
Named Entity Recognition is a subpart of Information Retrieval systems. Named Entities carry important information about the textual data being analyzed. If a system is devised to extract named entities from a document the accuracy of Information Extraction system can be increased many folds.
Named Entity Recognition is the offset of many important Information Retrieval tasks. For instance, Biomedical Information extraction tasks, event extraction, relation extraction systems, etc start with Named Entity Recognition.
#2 Machine Translation Systems
Computer linguistics is a field of study that deals with the application of computer science techniques to carry out linguistic analysis and synthesis. A subpart of computer linguistics is machine translation or conversion of speech or text from one natural language to another.
When it comes to machine translation named entities to prove especially tricky because their translation is based on language-specific rules. If the named entities are extracted before the actual translation the entire process becomes much more accurate.
#3 Efficient Semantic Annotation
Semantic annotation is the process of adding information to a document. This added information is generally named entities that can help machines understand the nuances of a textual document. Semantic annotations are aimed at enriching unstructured or semi-structured documents with domain-adapted structured relations.
NER systems can extract such annotations and relations increasing the efficiency of machine powered analysis. Such automation is carried out using NER systems, that are employed to identify concepts and relations that are worth annotating.
Named Entity Recognition has many diverse uses besides the ones mentioned above. For instance, NER systems have been used to solve complex problems related to text clustering, opinion mining, etc. In a previous post, we have discussed the applications and use cases of Named Entity Recognition systems in much greater detail.
We hope you liked the article. Please Sign Up for a free Komprehend account to start your AI journey now. You can also check out free demos of Komprehend AI APIs here.


